
This artcile’s dataset as well as our method’s source code that were used for validating our experiment are available to support the reproduction of our method and results, and can be obtained from my github repo
Deep neural network is a very powerful tool in machine learning. Multiple non-linear hidden layers enable the model to learn complicated relationships between input and output. However, when the training set is small, there are different parameter settings that would fits training set perfectly, but the one complex parameter setting tends to perform poorly on the test dataset, i.e. We got the problem of overfitting. One way to solve this problem is by averaging predictions of different neural networks , but this becomes computationally expensive when applied to large datasets. The alternative that makes it possible to train a huge number of different networks in a reasonable time is dropout, which randomly omits some hidden units i.e. feature detectors to prevent co-adaption and samples from an exponential number of different “thinned” networks.
The idea of dropout model can be shown in the 2012 paper of Nitish Srivastavanitish and Geoffrey Hinton. Applying dropout to a neural network amounts to sampling a “thinned” network from it, where you cut all the input and output connections for the dropped units. Training process for that would be like training a number of thinned networks with extensive weight sharing. But when it comes to testing, averaging predictions over different networks seems to be unfeasible, so a single network with scaled weights for all the units was used.
 |
|---|
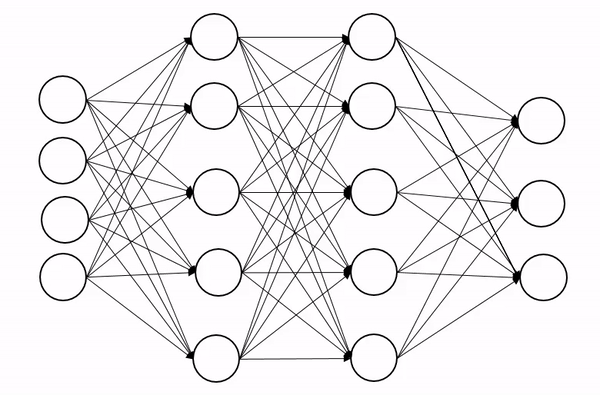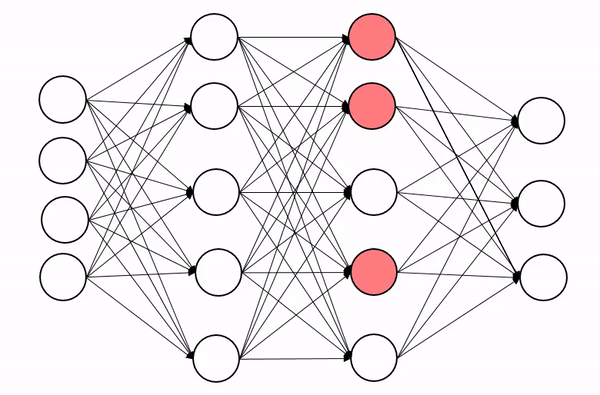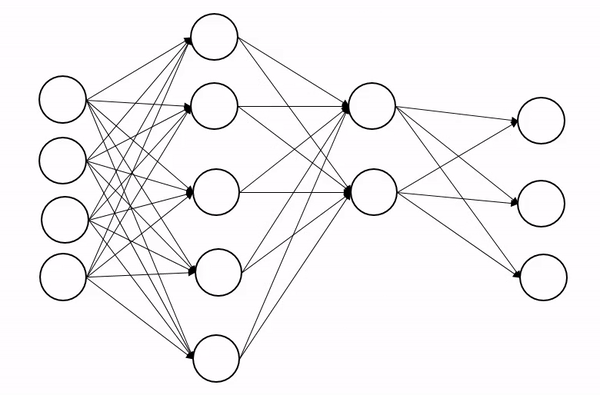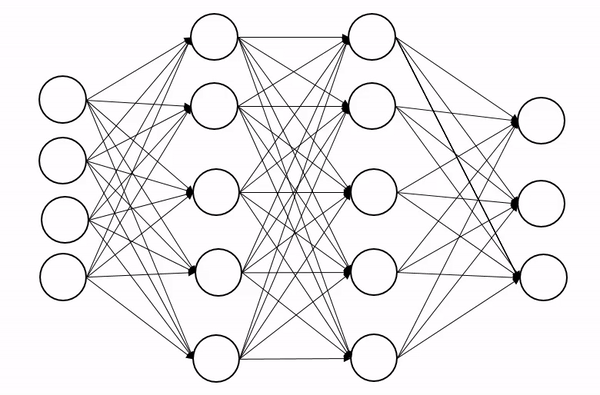
| Example of dropout applied on a second hidden layer of a neuron network |
Training with Drop Out Layers
Dropout is a regularization method that approximates training a large number of neural networks with different architectures in parallel. During training, some number of layer outputs are randomly ignored or dropped out. This has the effect of making the layer look-like and be treated-like a layer with a different number of nodes and connectivity to the prior layer. In effect, each update to a layer during training is performed with a different view of the configured layer. Dropout has the effect of making the training process noisy, forcing nodes within a layer to probabilistically take on more or less responsibility for the inputs. This conceptualization suggests that perhaps dropout breaks-up situations where network layers co-adapt to correct mistakes from prior layers, in turn making the model more robust.
Dropout is implemented per-layer in a neural network. It can be used with most types of layers, such as dense fully connected layers, convolutional layers, and recurrent layers such as the long short-term memory network layer. Dropout may be implemented on any or all hidden layers in the network as well as the visible or input layer. It is not used on the output layer.
Dropout Implementation
Adding dropout to your PyTorch models is very straightforward with the torch.nn.Dropout class, which takes in the dropout rate – the probability a neuron being deactivated – as a parameter.
self.dropout = nn.Dropout(0.25)
We can apply dropout after any non-output layer.
Dropout as Regularization
To observe the effect of dropout, train a model to do image classification. I'll first train an unregularized network, followed by a network regularized through Dropout. The models are trained on the Cifar-10 dataset for 15 epochs each.
Complete example of adding dropout to a PyTorch model
To learn more, run the complete code at github repo. Here are the result fot both accuracy and loss functions in training and testing stes.
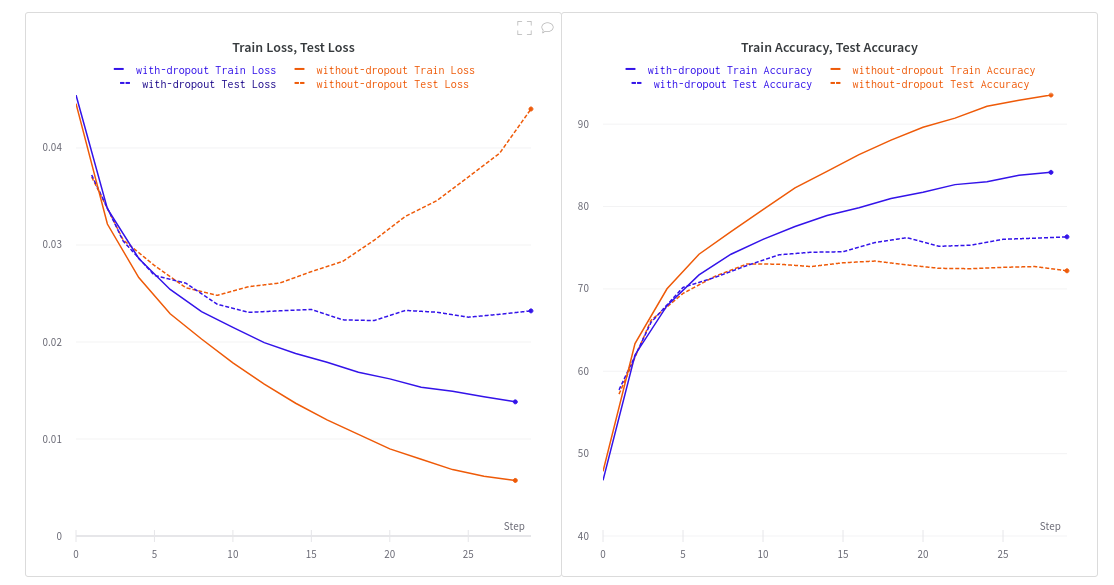 |
|---|
| Plots of accuracy and loss functions for 15 epochs |
Observations
An unregularized network quickly overfits on the training dataset. Notice how the validation loss for without-dropout run diverges a lot after just a few epochs. This accounts for the higher generalization error.
Training with two dropout layers with a dropout probability of 25% prevents model from overfitting. However, this brings down the training accuracy, which means a regularized network has to be trained longer.
Dropout improves the model generalization. Even though the training accuracy is lower than the unregularized network, the overall validation accuracy has improved. This accounts for a lower generalization error.
Reference
- Improving neural networks by preventing co-adaptation of feature detectors
- Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning
- Dropout: A Simple Way to Prevent Neural Networks from Overfitting
- https://wandb.ai/authors/ayusht/reports/Dropout-in-PyTorch-An-Example--VmlldzoxNTgwOTE
comments powered by Disqus